5 Steps to Effective Alert Management Workflows in Fleet Operations
A fleet of 500 vehicles can trigger over 1,400 fault codes a week that a fleet manager has to review for severity and closeout. Companies managing vehicle assets specifically rely on trusty fleet management systems to generate alerts of when an action needs to be made. However, the alert loses its value when the appropriate team members don’t respond to it accordingly and it leads to a major disruption such as an engine derate that requires a tow call. With their busy schedules and the large amount of data to manage, it’s understandable for fleet managers to occasionally overlook an alert. In fleet operations, this significantly impacts operational efficiency and vehicle reliability. This blog explores best practices for designing and implementing effective alert management workflows in fleet operations.
Introduction to Alert Management in Fleet Operations
Every fleet possesses its unique intricacies that cannot be fully accommodated by a standard, out-of-the-box fleet management alert system. For the alerts to be useful not only in your department but across the entire fleet, it takes some time to carefully set up alert triggers, customize notification methods, and prioritization. This process can seem overwhelming to do alone, so having a fleet management customer success team to help you customize your solution can make all the difference in streamlining this process.
Step 1: Establishing Clear Alert Criteria
Define Alert Triggers:
Defining clear criteria for what triggers an alert is the first step for setting up your alert management workflow. This involves setting thresholds for vehicle performance metrics, such as identifying clusters of fault codes that might indicate a malfunction in the DEF (Diesel Exhaust Fluid) tank level sensor, that may cause an engine to derate, at which point an alert should be activated. These can also include preventative maintenance (PM) reminders, work order assignments, recalls, or driver vehicle inspection report (DVIR) updates. In fleet operations, by setting clear trigger events, you guarantee that the appropriate team members receive timely notifications.

Step 2: Designing the Alert Notification Process
Customize Notification Methods:
In fleet operations, ensuring effective communication means selecting the most suitable notification types based on the team’s needs and their working environment. For team members who are often mobile, such as drivers, instant notifications like SMS alerts and phone calls can provide timely updates. For those in more stationary roles or who need detailed documentation, such as fleet managers, maintenance supervisors, or onsite technicians, a desktop dashboard or printed reports may be preferable. Each member should receive information in the format that best supports their immediate responsibilities and preferences. Using a tailored approach to building an alert management system will help improve the success rate of adoption across fleet operations.
Prioritize Alerts:
Not all alerts warrant the same level of urgency and too many alerts can create data overload that freezes decision-making. An intelligent fleet maintenance system like Pitstop can detect clusters of fault codes that historically have led to a breakdown. This would be prioritized as a critical alert that needs to be actioned immediately. Meanwhile, notifications of a less urgent nature, such as routine maintenance reminders, are still promptly addressed but do not detract from the attention given to more pressing issues. Each priority-level alert should receive the appropriate response based on its impact on the fleet’s safety and operational integrity.
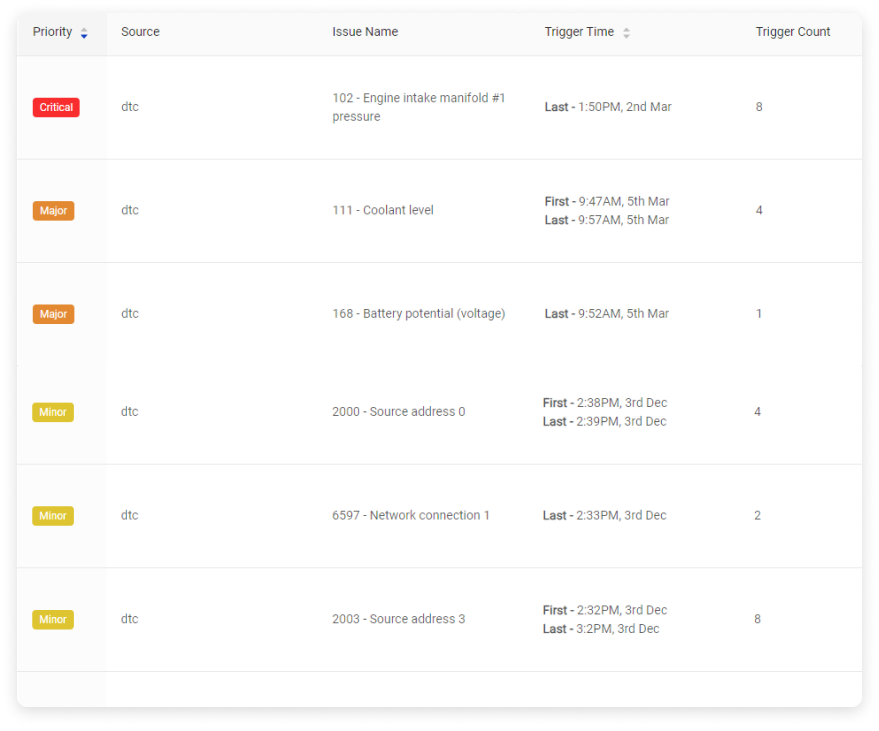
Step 3: Implementing Response Protocols
Define Response Actions:
When an alert pops up, following set guidelines helps fleet personnel decide the appropriate steps to take, such as printing a report, arranging for maintenance, or starting an inspection right away. These clear protocols simplify the decision-making process, ensuring the vehicle is swiftly repaired rather than remaining inoperative. This may require adjustments in shop workflow, considerations of cost, or modifications to triaging procedures. Collaborating with team members across departments is crucial for subtly improving workflows post-alert without causing friction. It involves deciding on processes that are both manageable and efficient consistently.
Pitstop outlines straightforward changes that can be readily implemented, alongside more complex adjustments that may require additional effort and planning. They help answer questions like “What kind of people would a typical person be expected to contact? What does the current workflow look like? Where can improvements be made or need coaching on?”

For example, an easy adjustment in the shop could be printing a Vehicle Health Report right before a vehicle comes in for a PM, helping the mechanic prepare for repairs with a maintenance checklist, and spending less time on diagnosis.
A more complex example involves identifying which PM tasks will require more time and adjusting the schedule to accommodate them. By adopting a triage approach to PM scheduling, it’s possible to increase the average time between maintenance activities, thereby reducing monthly maintenance costs without significantly increasing the risk of breakdowns or failures.
Step 4: Analyzing Alert Outcomes
Feedback Loop:
Analyzing the outcomes of alerts and the effectiveness of the response is crucial for continuous improvement. This involves reviewing the resolution of issues flagged by alerts, assessing the timeliness of the response, and adjusting alert criteria and response protocols as necessary. A key strategy is to incorporate an agile feedback mechanism, where data from resolved issues are systematically reviewed. This review should include an assessment of whether the alert criteria are still relevant and if the response protocols need adjustments for better efficiency.
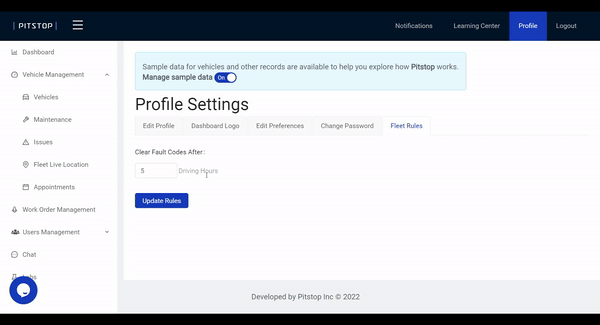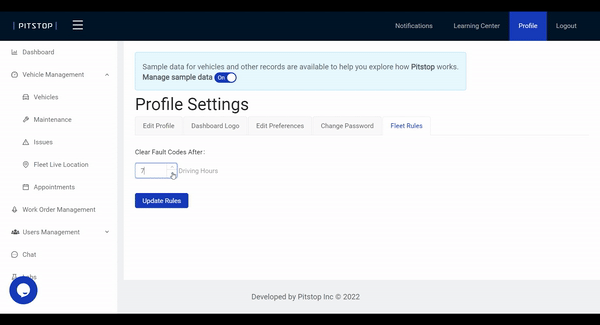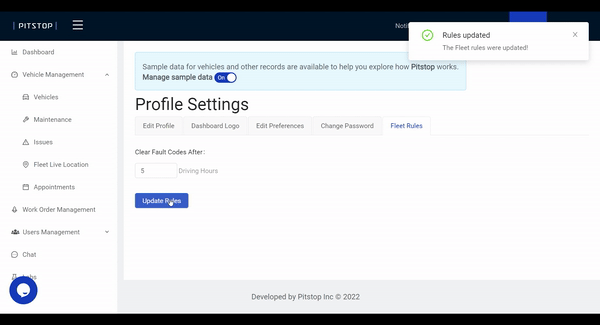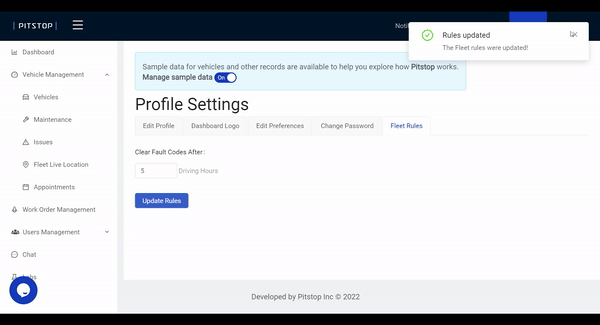
Pitstop offers a feature where fleets can create a custom rule that will clear a fault code if it is not triggered within a set number of engine hours. For example, encountering a minor issue like SPN 1807 – Steering Wheel Angle without a repeated fault code could indicate an accidental trigger. But if it was triggered multiple times, then this is something you want your mechanic to check out during the next PM. To prevent over-maintenance, you could set the clearing rule to 5 engine hours.
Step 5: Continuous Improvement and Adaptation
Iterative Refinement:
The dynamic nature of fleet operations requires an ongoing evaluation and refinement of alert management workflows. Incorporating feedback from drivers, mechanics, and shop supervisors, along with data analytics, supports the iterative improvement of the alert system. The involvement of a dedicated solution, such as Pitstop, plays a crucial role. This onboarding team is responsible for conducting regular reviews, suggesting modifications, and measuring the effectiveness of the alert management system across the entire fleet. Ensuring the alert management system is finely tuned can have a profound impact on the fleet’s success.
Beyond the Alert – A New Horizon for Fleet Management
The true measure of an effective alert management workflow in fleet operations extends far beyond the immediate response to alerts; it encompasses the entire lifecycle of fleet management, from preemptive measures to post-alert analysis and beyond. By fostering a meticulous and adaptive approach to implementing these workflows, fleet managers can ensure their teams are not just reacting to issues but are proactively managing the fleet’s health and efficiency.
As we consider the transformative potential of well-managed alert systems, we are invited to envision a future where fleet operations are not just about managing vehicles but about nurturing a dynamic ecosystem that learns, adapts, and thrives on every alert. This vision challenges us to rethink the role of alerts not as mere notifications of what has gone wrong, but as opportunities for growth, innovation, and continuous improvement.